Managing Data Consistency in a Microservice Architecture

Share This Article
Modern commerce and microservices
Table of Contents
Subscribe to Our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.
In a microservices architecture model, it is common for an atomic logical operation to span across multiple services. It is sometimes true that even monolithic systems use multiple databases for ensuring consistency. When there are many independent storage solutions, there is always the risk of inconsistent data which can ultimately prove to be a disadvantage for the users of microservices. This blog post deals with the different methods that support data consistency between microservices.
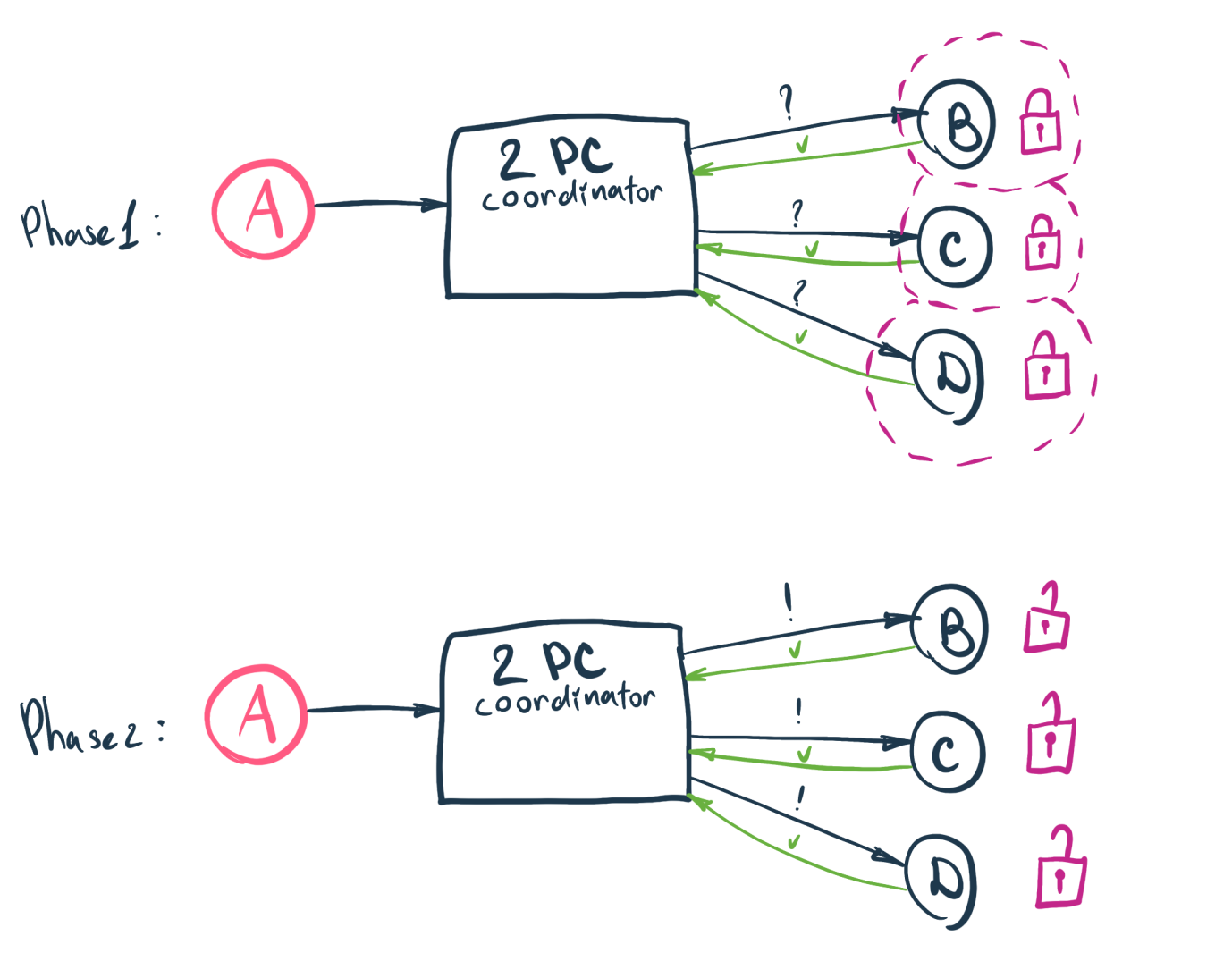
The basic challenge of maintaining data consistency in microservices architecture is that there are multiple spots where the data is stored. Using the XA protocol to implement the two-phase commit (2PC) pattern forms one method by which this problem can be managed.
However, in the modern cloud environment, 2PC does not help to solve the problem completely. Different methods according to specific requirements have been proposed to manage these microservices architecture data consistency challenges.
Saga Pattern
The SAGA pattern is used to handle data consistency issues in systems with multiple microservices. SAGAs may be treated as an application-level distributed coordination of multiple transactions. Individual SAGA implementations may be optimized according to use-case requirements.
Read our blog “How to Handle Failed Transactions in Microservices”.
It can frequently happen that any atomic business action spanning many services can give rise to multiple transactions. The SAGA pattern works on the central idea of being able to roll back just one of the transactions. Though ‘rollback’ may not be possible for individual transactions that are already ‘committed’, this may be achieved by invoking a compensation ‘Cancel’ operation.
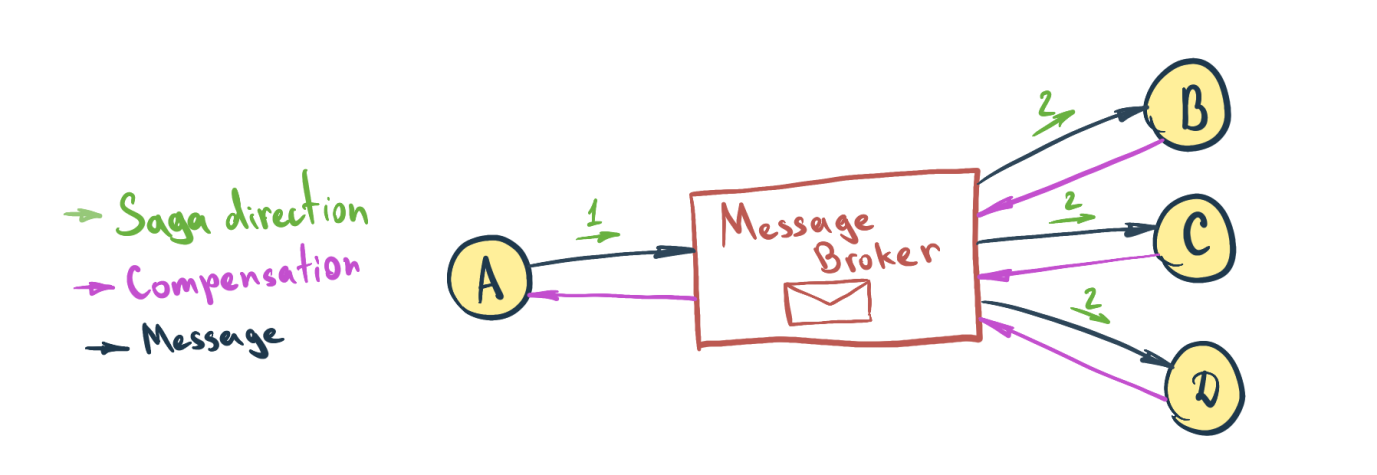
Compensating Operations
It is also important to try and implement services that are idempotent or unchanged so that certain operations can be restarted in case of failures. It is vital to monitor failures and design reactions that are proactive.
Reconciliation
If the system responsible for compensation crashes in between, the user should receive an error message and either the compensation logic should be triggered or the execution logic should be resumed when asynchronous user requests are processed.
Main Process Failure
To apply for compensation, data from multiple services should be reconciled. Reconciliation is done in a manner much similar to that in financial transactions. In microservices, data from multiple services are reconciled based on action triggers. These actions can be triggered based on a schedule or via a monitoring system for failures. A record-by-record inspection is a good method. Aggregated values are compared and one of the two systems can be designated as the source of true data for each record.
Read our blog: Why have big companies like Amazon and Netflix adopted Microservices?
Event Log
For multi step transactions, the best method to determine which of the transactions may have failed during the process of reconciliation is to check the status of each of the transactions. If a stateless mail service sends an email or produces other kinds of responses, this function will be likely unavailable. In other cases, if you want immediate visibility on the state of the transaction, especially in complex scenarios, this will be unavailable. As an example, it may be a multistep order for booking hotels, flights, and transfers.
Are you looking for a microservices vendor? Call SayOne or drop us a note!
Complex Distributed Process
An event log can help in complex distributed processes. Logging is a simple technique but a powerful one. “Write-ahead logging” is a method that databases use to achieve or maintain consistency between internal data replicas. The same technique can be applied to microservices design also. Here, ahead of making any actual data change, the service writes a log entry about the intent to make the change. Practically, this log could be a table/collection inside a database owned by the service that coordinates.
Read our blog : Building Microservices Application Using Spring Boot & Cloud
The event log can be used to resume transaction processing and provide visibility to system users, particularly, the customers or the support team. However, in simple scenarios, a service log may be redundant. Here, status endpoints/status fields may be enough.
Orchestration and Choreography
SAGAs can be used as part of both orchestration and choreography scenarios. Here, each microservice knows of just a part of the process. Sagas know about handling both positive plus negative flows of distributed transactions. In the choreography part, each distributed transaction participant has this knowledge.
Single-write with Events
A simple data consistency solution is to modify a single data source at a time. Here, changing the state of the service and emitting this event as a single process, these two steps are separated.
Change-first
Considering a major business operation, you can modify your state of the service and a separate process can reliably capture the change and then produce the event. This technique is given the name ‘Change Data Capture (CDC)’. Some of the technologies used in implementing this approach include Debezium/ Kafka Connect.
Read our blog: How to Build a Microservices Application
Changing Data Capture using Debezium/Kafka Connect
No specific framework is required in some cases. Databases sometimes offer a friendly method to tail operations logs (e.g., MongoDB Oplog). In the case of no such functionality available in the database, changes may be polled by timestamp or queried using the last processed ID for the immutable records. You can avoid inconsistency by making the data change notification a separate process. The database record here is the single source of truth. A change is captured if it happened at all.
Changing Data Capture without Specific Tools
The biggest drawback of the change data capture method is the separation of business logic. Change capture procedures exist in the code base and lie separate from the change logic and this is inconvenient. A very well-known application of change data capture is a domain-agnostic change replication in which data is shared with a data warehouse. For domain events, it is a good idea to employ a different mechanism (sending events explicitly).
Event-first
Instead of writing to the database first, we can strive to trigger an event and share it with ourselves and other services. Here, the event turns out to be the single source of truth. This is a form of event sourcing in which the state of our service becomes a read model and each of the events is a write model.
Download our eBook “Porting from Monolith to Microservices – Is the Shift Worth It”.
Event-first Approach
Though the event-first approach is a command query responsibility segregation (CQRS) pattern in which we separate the read and write models, the CQRS by itself does not focus on consuming the events with multiple services.
Event-driven architectures are designed to focus on events consumed by multiple services but do not place enough emphasis on the fact that events are the singular atomic pieces of data update. The internal state of the microservice can be updated by emitting a single event to the originating service and any other microservices (that are interested).
The usual way to tackle event-first challenges is to use optimistic concurrency by placing a read model version into the event and ignoring it on the consumer side if in case it has been already updated on the consumer side. Another solution could be to use pessimistic concurrency control by creating a lock for an item when checking its availability.
Download and read our eBook “MICROSERVICES- A Short Guide”.
Another challenge of the “event-first” approach is the order of events. In case events are processed in the wrong order by many concurrent consumers, there may occur a different kind of consistency issue as in processing an order for a customer that is not yet created.
Kafka or AWS Kinesis (data streaming solutions) can help to guarantee that events related to a single entity will be sequentially processed (creating an order for a customer only after creating the user). Kafka allows you to partition topics by user ID and all events related to a single user will be processed by one consumer that is assigned to the partition, and this is sequential. However, in Message Brokers, though message queues have an order, multiple concurrent consumers make message processing in a sequential order difficult, almost impossible.
The “event-first” approach is hard to implement practically in those scenarios when linearizability is required or in those that have many data constraints (like uniqueness checks). However, it is suitable for other scenarios. Because of its asynchronous nature, concurrency challenges and race conditions still have to be overcome.
Consistency by Design
There are different ways to split the system into many services. We always try to match separate microservices with separate domains. Sometimes it’s hard to differentiate domains from subdomains or aggregation and make them more granular.
Are you thinking of shifting to microservices to help your business grow? Call SayOne today!
Instead of focusing on only domain-driven design, it is important to consider how well microservices isolation aligns with transaction boundaries. A system in which only transactions reside within microservices does not require the above solutions. Transaction boundaries should be considered when designing the system. Though it may be hard to design the whole system in practice, it is important to minimize data consistency challenges.
Accepting Inconsistency
There are also many use cases when consistency is not very important. When gathering data for analytics or statistical purposes, even a 10% random data loss from the system will not affect the analysis values.
Sharing Data with Events - Which Solution is Best
An update of data at atomic levels requires a consensus between two systems (whether a single value is 0 or 1). In microservices, the problem is one of consistency between two participants and the single rule of thumb that we can follow is:
At any given moment, for every data record, you have to find out which data source is trusted by the system.
The source could be events, the database, or one of the services. Achieving consistency in microservices systems is the developers’ responsibility.
Conclusion
For data consistency,
- It is a good idea to design a system that does not require distributed consistency. This is barely possible for complex systems.
- You can try and reduce the number of inconsistencies by the modification of one data source at a time.
- Consider event-driven architecture. The event-driven architecture allows loose coupling and has events as a single source of truth.
- Designing your service capabilities to be reversible is yet another method. You can decide how you will handle failure scenarios and try to achieve consistency in the early design phase.
Share This Article
FAQs
Data consistency is a support for data integrity and it ensures that all the users share the same view of the data, even if changes were made by the user or by others.
we can ensure data consistency by: Using referential integrity to ensure that data is consistent across tables, Using locks to ensure that data remains consistent even when multiple users try to access the same data simultaneously, Checking data consistency
ACID is designed to capture the essential characteristics that a strongly consistent database displays. ACID expands to: Atomicity: If any part of the transaction fails, the whole operation is rolled back. Consistency: The database remains structurally strong even after every transaction. Isolation: Each transaction is completely independent of another transaction. Durability: All transaction results are always preserved.
The SAGA approach guarantees ‘availability’ over ‘consistency’. This means that that data will be eventually consistent. This is one of the most common approaches to enforcing data consistency in microservices architecture design.
Subscribe to Our Blog
We're committed to your privacy. SayOne uses the information you provide to us to contact you about our relevant content, products, and services. check out our privacy policy.



